1. 简介
libeasy网络框架包含了基础数据结构、内存管理、线程池、io管理以及包处理等模块,本文分析的是基础数据结构模块。基础数据结构模块包括简单的内存池、缓冲区管理、链表、数组、字符串、哈希表等。
2. 简单内存池
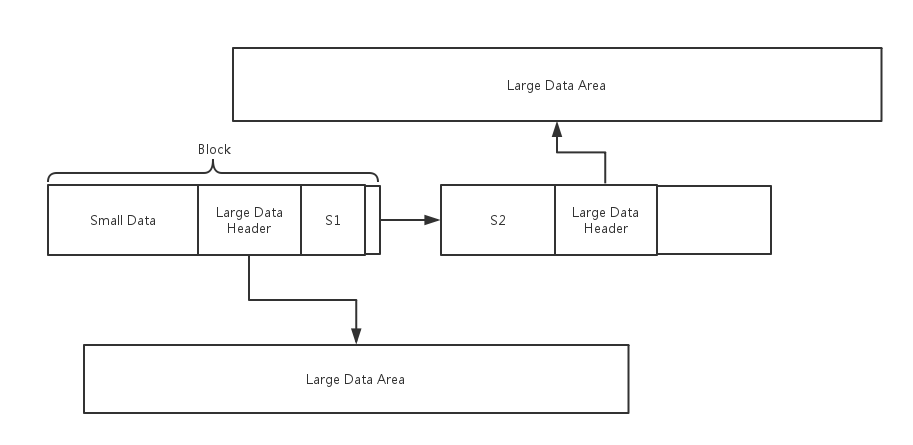
libeasy内存池的内存分配情况如上图所示,主要有两种大小的内存,一种是默认的小块内存,称为Block;另一种是大块的内存,用于存放大块内存申请的数据部分,称为Large Data Area。
Block的大小是固定的,由内存池的使用者在初始化的时候指定,其用于存放申请的小块内存的Header和Data部分,以及大块内存的Header部分,多个Block之间采用链表的方式链接。Large Data Area的大小不是固定的,由用户申请的内存大小决定,但一定比Block要大,用来存放大块内存申请的数据部分。
以小块内存申请和大块内存申请的过程来讨论libeasy内存池的管理:
2.1 小块内存申请
如图所示,假设申请的内存空间为S1字节,其中S1小于Block的大小。libeasy会从资源池的某个Block开始遍历,寻找Block剩余空间能容纳下当前申请S1字节的空间,则在当前Block分配存储空间;如果要申请的内存空间S2比当前所有Block的剩余空间要大,那么需要重新分配Block来存放。
2.2 大块内存申请
如图所示,当申请的内存空间的大小大于Block时,说明任何一个Block都不可能存放下,此时,libeasy采用的方式是完全重新分配一块内存空间,大小正好和申请的内存空间大小相同,用于存放数据部分,而头部字段则还是存放在Block中。
注意:大块内存申请的时候有头部字段,主要用于将Large Area Data用链表方式串联起来,方便后续释放Large Data Area的内存空间。
另外,这里小块内存申请的时候是没有头部字段的,所以,小块内存申请的空间是不允许释放的(如果可以释放,需要管理Block内部的内存碎片,会使得资源池管理复杂),libeasy只允许以整个内存池为单位来进行内存空间的释放,这种方式是会造成一定程度上的内存空间浪费的,有可能Block中或Large Data Area中有部分数据不需要使用可以释放,但用户无法主动释放。
3. 缓冲区
libeasy中的缓冲区包括三种,字符串缓冲区、普通缓冲区和文件缓冲区。
3.1 字符串缓冲区
其定义如下
1 | struct easy_buf_string_t { |
相对于C的普通字符串,多了一个字段记录长度信息。字符串缓冲区的内存申请都是使用简单内存池的接口,以其中的缓冲区copy函数为例来说明
1 | int easy_buf_string_copy(easy_pool_t *pool, easy_buf_string_t *d, const easy_buf_string_t *s) |
如上所示,目标d直接从简单内存池中申请内存空间,然后使用memcpy把源字符串缓冲区内容拷贝过来。
注意:这里d之前的内存空间如果不是采用简单内存池方式申请,那么需要先释放,否则会造成内存泄露。如果是从简单内存池申请的,则会有内存池最后清理的时候释放空间。
3.2 普通缓冲区
普通缓冲区的结构体如下
1 |
|
其中,最关键的三个字段,pos,last和end的关系如下图。
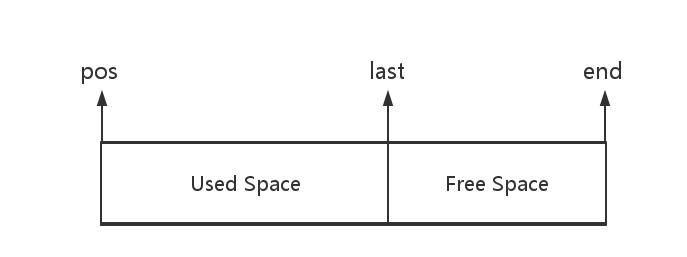
pos代表缓冲区的开始部分,last则表示缓冲区已经使用的部分,end表示缓冲区末尾的部分。
libeasy在对读写缓冲区的管理上有所区别,如下
- 对于读缓冲区,如果有个请求申请的空间大于其剩余空间,它会以1.5倍当前空间重新从简单资源池申请空间,然后把原先缓冲区的内容拷贝进去。
- 对于写缓冲区,如果申请的空间大于其剩余空间,则会重新申请一个easy_buf_t,然后通过链表的方式串联在之前缓冲区的后面。
个人认为,libeasy对于读写缓冲区管理不同的原因在于,对于server端,读到的数据量往往比较小,通常不需要扩展缓冲区的内存空间,而对于写来讲,一般数据量可能会比较大,所以,采用缓冲区链的方式,避免内存的多次重复拷贝。
3.3 文件缓冲区
文件缓冲区的结构体如下
1 | struct easy_file_buf_t { |
比较特殊的是增加了fd,offset和count字段。fd是文件描述符,offset是要读写的偏移量,count目前还不清楚用来做什么。
另外文件缓冲区还会在flag字段设置EASY_BUF_FILE以区别普通缓冲区,对于一个操作完成的文件,可以设置EASY_BUF_CLOSE_FILE,来标识文件需要关闭。
4. 链表
libeasy的双链表是借鉴linux内核双链表的,所以,本节以linux内核双链表为例来说明。
首先,先说明一下为什么需要单独的写双链表,直接在结构体里面写struct XXXType *next不就完了吗?
4.1 为什么不采用普通的结构体定义next指针的方法?
在学数据结构时,我们经常用的定义双链表的方法这样的
1 | struct linklist |
这么定义的话,一般会有下面几个缺点:
一个结构体对应多个链表的话,那么需要定义多次next和prev指针,比如,有一个结构体定义如下:
1 | struct student |
如上代码所示,一个学生属于整个学校的学生中的一个,所以,整个学生的学生组成了一个链表(all_next),而学校里面每个年级也有相应的学生,为了快速管理某个年级的学生的信息,那么需要把某个年级的学生串成一个链表(m_next),那么这样的话,每次学生有个新角色要加入,都必须加入对应的链表的prev和next指针,并且,对应的遍历等操作也需要增加新的代码。
针对struct linklist写出来的代码可能不具有通用性,针对每一种ElementType,可能对应的代码都需要做相应的变化,造成linklist需要维护大量的额外的信息(每种ElementType可能只用到了其中的一种)
4.2 linux内核双链表
由于上面的缺点,linux内核中使用的双链表,把数据和链表结构分开,完美了克服了普通链表的缺点,其定义一般为如下:
1 | struct list_head{ |
这是通用的链表结构,在我们需要使用链表的结构体中,定义一个它就能使用通用链表提供的插入,删除,遍历等等操作了。
1 | struct node |
先以一个例子来说明
1 |
|
4.2.1 原理
细心的朋友可能看到,在遍历双链表的时候,明明程序就只有一个头节点,类型为struct list_head,那么怎么能就获取到类型为 struct test对应结构体的指针呢?
关于这个问题,需要理解两个宏,首先是
1 |
首先是根据结构体中某个变量的名称来获得其在结构体中的偏移的宏,仔细看上面的定义:
(type *)0,把0强制类型转换成type *((type *)0)->member), 把0看成结构体的开始地址,那么member成员所在的地址就是member在结构体的偏移量&(((type *)0)->member))则就是获取地址偏移量- 最后用size_t转成可移植的偏移量,在32位系统中是32位,在64位系统中是64位。
理解了第一个宏之后,我们先来回顾一下上面遍历的代码:
1 | list_for_each(pos, &head) //遍历链表 |
有了上面的offset宏,我们可以想到的是,我们先由pos指针的值和pos结构体的entry变量的偏移量相减,得到结构体的对应的内存地址,然后再强制转换成(struct test *)即可,这也就是第二个要理解的宏所实现的功能:
1 |
- 先定义了一个指针,其值等于ptr
offsetof(type, member)):获取ptr在struct的member相对于struct起始地址的偏移量- 因为offsetof等到的是个整数,为了准确减去这个整数,需要先把_mptr转成char *类型,一个
sizeof(char) == 1 - 最后把得到的结构体的地址强制类型转换成
struct type *,这样就能得到结构体的地址了。
有了上面两个宏,实现双链表的各种操作就不难了,由于offsetof和container_of是定义在linux的标准库里面的,所以linux的双链表移植性不好,所以libeasy自己实现了类似的一套操作,这里不再赘述。
5. 数组
libeasy的数组的结构体定义如下
1 | typedef struct easy_array_t { |
其中pool是用来申请内存空间的简单内存池,list用来存free list,分配内存时优先从free list拿,拿不到再去pool里面申请。object_size记录的是单个array元素的size,count则是free list的元素个数。
array主要涉及到alloc和free操作。
alloc
- 先看free list是否为空,若不为空,则从free list里摘取一个元素
- 如果为空,则从pool申请一个元素
free
- 把释放的元素放到free list中
6. 字符串
libeasy的easy_string中并没有定义新的字符串相关的类型,而是实现了一些字符串相关的操作,例如strncpy,toupper,tolower之类的,属于常见的C语言的字符串操作,这里不就详细讲了。
7. 哈希表
哈希表主要考虑的几个因素包括,哈希函数、解决冲突的方法和扩张的时机。
7.1 哈希函数
libeasy里面普通的哈希表和针对字符串的哈希函数不一样,猜测是针对字符串的是更好的在多个哈希桶之间做均衡。
7.2 解决冲突的方法
libeasy里解决冲突的方法采用的是开链法,即每个桶对应的其实是一个链表,如果在某个key产生冲突的话,则放到相同的链表上即可。
工业界的哈希表中大多数都是采用这种方法来做的,例如memcached和redis。
7.3 扩张的时机
当哈希表的元素个数增加较多时,会造成哈希桶的链表中有较多的元素,这样每次查找时,都得遍历哈希桶的链表,才能找到对应元素。哈希表的元素越多,每个哈希桶的链表上的元素就越多,这样查找的效率就越低。
为了避免上述情况,一般在哈希表元素/哈希桶个数超过某个比例时,就会考虑哈希表扩张,即增加哈希桶的数目,从而来减少每个哈希桶上的元素个数,提升查找效率。
在libeasy中,并没有实现哈希表扩张的功能,不过在memcached和redis有实现,后续会讨论相关的实现。
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。
