引言
前一篇文章中,介绍了ANSI SQL标准下的事务隔离级别及其扩展,这篇文章主要讨论了基于加锁的方式如何实现不同的事务隔离级别,全文的组织架构如下:
- ANSI SQL标准下的事务隔离级别及其扩展回顾
- 基于加锁方式的事务隔离原理
ANSI SQL标准下的事务隔离级别及其扩展回顾
ANSI SQL标准下的事务隔离级别是基于禁止某些干扰现象而制定的,这些现象如下:
脏读P1
W1(X)…R2(X)…A1…R2(X)
不可重复读P2
R1(X)…W2(X)…C2…R1(X)
幻读P3
R1(P)…W2(P)…C2…R1(P)
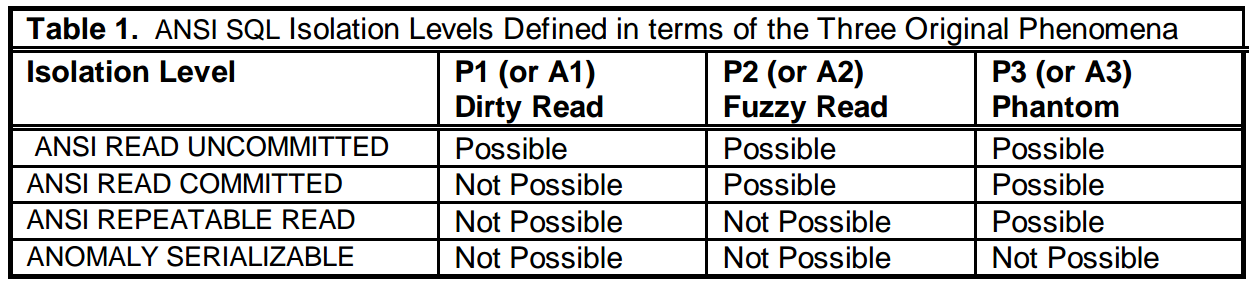
针对三种现象,ANSI SQL标准设定了四种事务隔离级别,如下:
- Read Uncommitted:有可能发生P1,P2和P3
- Read Committed:不可能发生P1,有可能发生P2和P3
- Repeatable Read:不可能发生P1,P2,有可能发生P3
- Serializable:不可能发生P1,P2和P3
整个事务个隔离级别,与杜绝的现象的对应关系如下图:
由于ANSI SQL的标准存在以下限制:
- 没有提及写操作的隔离性
- ANSI SQL的标准比较老,对于采用多版本并发控制实现隔离性的级别不能够很好的描述
即新干扰现象P0和P4,其中脏写P0如下
W1(X)…W2(X)…A1
写丢失P4如下
R1(X)…R2(X)…W2(X)…C2…W1(X)…C1
因此,引入了新的隔离级别,包括
- Cursor Stability
- Snapshot
具体的分析,请参照我的博文(事务隔离(一):ANSI SQL事务隔离级别,限制及扩展)。
基于加锁方式的事务隔离原理
基本概念
锁有两种,即共享锁(Share Lock)和排他锁(Exclusive Lock),对于不同事务加在同一个数据项上的锁,如果其中至少有一个是排他锁的话,那么事务是会冲突的,即其中一个事务必须等待。一般共享锁也称为读锁(Read Lock),而排它锁也称为写锁(Write Lock)。
读写锁根据锁住的数据项不同,分为普通锁和谓词锁。谓词锁是指锁住满足某一查询条件的所有数据项,它不仅包括当前在数据库中满足条件的记录,也包括即将要插入,更新或删除到数据库并满足查询条件的数据项。对于不同事务加在查询条件下的谓词锁,在至少一个是写锁的情况,且两个谓词条件中包含重叠的数据项时,则两个事务是冲突的。
well-formed read(write)是指在read(write)一个数据项或者查询条件时,会先对数据项或者查询条件加read(write) lock。如果一个事务的所有读写都是well-formed,那称事务是well-formed。
two-phase read(write)是当有一个或多个read(write) lock被释放后,不能再加新的read(write) lock。如果一个事务在释放一个或多个锁后,不再加其他的锁,那么称该事务是two-phase的。
如果一把锁从加上,到事务结束(commit or abort)后才释放,则称此锁是long duration的,否则,称锁是short duration的。
多个并发执行的事务是serializability,指的是并发调度执行的结果等于这些事务某个串行执行的结果。例如,有三个并发执行的事务T1,T2和T3,如果其执行结果和其某个串行执行((T1,T2,T3),(T1,T3,T2),(T2,T1,T3),(T2,T3,T1),(T3,T1,T2),(T3,T2,T1))的结果相同。
如果一个事务T1持有一把锁的情况下,另一个事务T2申请一把冲突的锁,那么,事务T2只有等到事务T1释放这把锁之后,才能加上这把锁。
根据数据库的基础理论,采用well-formed two-phase locking方式调度事务的话,是能够保证serializability的。
在了解到锁的基本概念之后,接下来讨论,如何基于锁来实现各种不同的隔离级别。
隔离级别如何实现
先来看所有的干扰现象:
脏写P0
W1(X)…W2(X)…A1
脏读P1
W1(X)…R2(X)…A1…R2(X)
不可重复读P2
R1(X)…W2(X)…C2…R1(X)
幻读P3
R1(P)…W2(P)…C2…R1(P)
写丢失P4
R1(X)…R2(X)…W2(X)…C2…W1(X)…C1
如果需要禁止P0,即禁止多个事务同时能修改一个数据项或谓词条件,则需要修改数据时,加写锁,并且是long duration的,此时,隔离级别满足Read Uncommitted。
如果需要禁止P1,即禁止读取到其他事务修改的中间状态的数据,在禁止P0的条件下,则需要,对读加锁,short duration的就能够满足条件,此时,隔离级别满足Read Committed。
如果需要禁止P4,即禁止事务读取并且修改某个数据项后,需要禁止其他事务再次修改,但如果只是读取的话,不影响,这里,需要一种特殊的锁,称为Cursor Lock,会对事务当前处理的行进行加锁,如果行记录被修改,那么锁会是long duration的,直到事务结束,如果,行未被修改,则锁会提前被释放,此时,隔离级别满足Curstor stability。
如果需要禁止P2,即要禁止到读到某个数据项后,该数据还可能被其他事务修改,因此,需要对读加锁,且一直加锁到事务结束,即long duration,此时,隔离级别满足Repeatable Read。
如果需要禁止P3,即要禁止读到某个谓词条件后,满足该谓词条件的数据还被其他事务修改,因此,需要对谓词条件加读锁,且是long duration的,此时,隔离级别满足SERIALIZABLE。
不同的加锁与事务隔离级别的对应关系如下: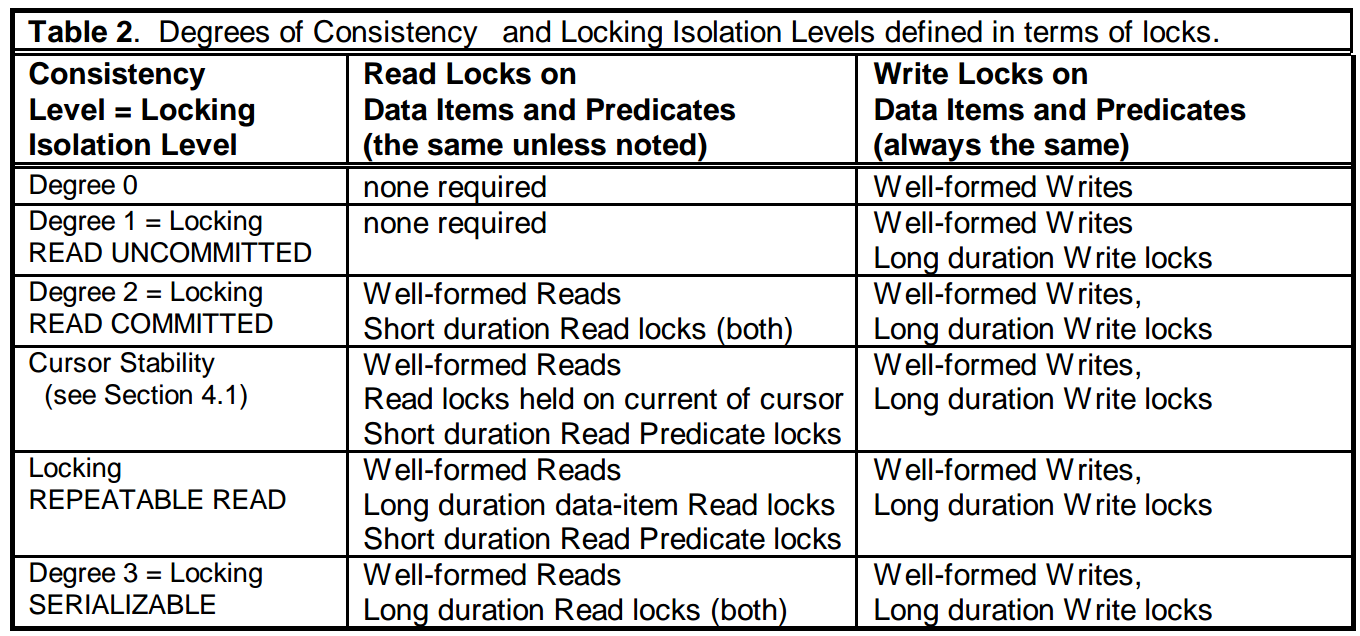
表格中最后一项中,对于读写锁都是long duration的,即到事务结束才会释放锁,即事务过程中只有加锁阶段,没有解锁阶段,这种方式和普通的two-phase locking有什么区别呢?
Two-phase Locking
普通的two-phase locking包含两个阶段:
- Expanding phase:加锁阶段,此阶段只加锁,不释放锁
- Shrinking phase:解锁阶段,此阶段只解锁,不加锁
普通的two-phase locking可能会如下问题:
假设有两个事务T1,T2,它们的时序如下
1 | T1 T2 |
由于事务T2读到的数据是事务T1修改的X,当事务T1回滚时,事务T2读到的数据就是脏数据,因此,需要对事务T2也进行回滚,如果存在T3也读到了T2修改的数据,那么T3也需要回滚,这样,会导致一系列的事务都需要回滚,称为Cascading Aborts。
而表格中的two-phase locking,只有加锁阶段,因此,不会存在上述问题。只有加锁阶段的two-phase locking,也称为strict two-phase locking。
由于two-phase locking采用的是加锁的方式,因此有可能会碰到经典的死锁问题,举个例子,如下:
假设有事务T1,T2,它们的加锁时序如下:
1 | T1 T2 |
按照如上的时序,事务T1和T2处于等待互相释放锁的状态,即死锁。死锁问题会导致事务无法继续进行有效的工作,因此,必须要解决,常见的解决方案有:
- 死锁检测并消除
- 锁等待一段时间阈值后,对事务进行回滚,并释放所有锁
第一种方法,死锁检测并消除的方法是有一个单独的线程检测事务的锁等待图,如果图构成了一个环,那么,说明发生了死锁,此时,需要选择环中的一个事务进行回滚,并释放锁,使得其他事务能够继续运行下去。
第二种方法,锁等待一段时间阈值后,对事务进行回滚,并释放其所有锁,表明,每次发生死锁时,都会先回滚最早开始执行的事务,使得其他的事务能够继续运行下去。
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。
