引言
F1是Google自主研发的分布式数据库,采用计算与存储分离的架构,存储层采用Spanner作为分布式KV存储引擎,计算层则是F1团队研发的分布式SQL引擎,其整体架构如下图
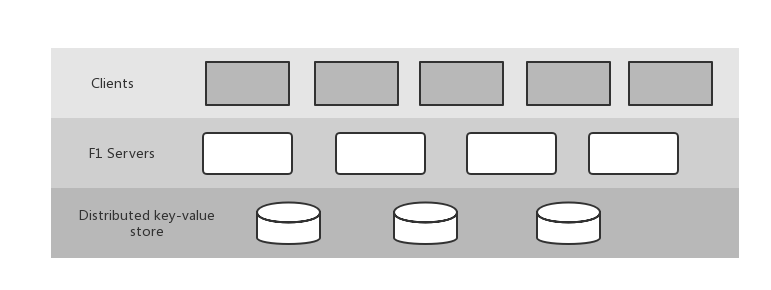
存储层向SQL层(F1 Server)提供KV操作接口,而SQL层负责将用户请求的关系Schema数据转换成KV存储格式。在此架构下,F1有以下特点
- 共享的存储层:所有的F1 Server共享存储数据,F1 Server不再做数据划分;
- 无状态的计算层:F1 Server层是无状态的,因此,同一个事务的不同语句是可能在不同的F1 Server执行的;
- 无全局的成员列表:由于F1 Server层是无状态的,因此,没有维护全局的F1 Server的成员列表;
- 关系性Schema:每个F1 Server都有一份关系型Schema的拷贝,F1 Server会将关系性请求映射成分布式KV存储能处理的请求;
- 大规模:F1 Server的规模通常是成百上千,其上运行的业务量较大。
根据F1的上述特点,对其Schema变更需要有如下需求
- 保持数据可用:由于集群规模大,Schema变更时需要保证数据是持续可用的,这意味者不能采用如加锁等简单粗暴但影响业务的变更方式;
- 异步的Schema变更:由于没有全局的成员列表,无法保证所有F1 Server同步地获取到同一个版本的Schema,因此,Schema变更时需要能够支持F1 Server异步的Schema变更;
- 对数据访问的性能影响较小:Schema变更属于后台任务,应该对前台的用户请求保持较小的性能影响。
针对上述Schema变更需求,F1团队分析了异步的Schema变更可能导致的数据不一致的问题,提出了一种安全的Schema变更算法。本文将先简单介绍KV存储引擎的提供的接口,然后分析异步的Schema变更导致的问题,最后再描述F1的Schema变更算法以及其限制点。
KV存储引擎
F1 Server所依赖的存储引擎需要提供三个操作接口:
- put:更新或者插入一条KV记录;
- del:删除一条KV记录;
- get:获取一条或多条KV记录,匹配提供的Key的前缀
除此之外,还需要提供如下语义保证:
- Commit Timestamps:每个KV记录都会存储修改时间;
- 原子的批量读写:支持原子的执行多条get和put操作。
由于F1对外提供的是关系型的Schema,因此,F1 Server负责将关系型Schema的数据转换成相应的KV记录。在关系型Schema中,最常用的Schema元素是表格,表格的Schema定义中一般会包含多个列定义,其中会在多列中选取其中的某一列或者几列来作为主键列,主键列能唯一的标识一行。很自然地,将表格的一行存储为KV记录时,会选取主键列的列值作为Key,F1并没有简单的采用将关系表格中的一行映射成一条KV记录的方法,而是将除主键列之外的每列都其映射成一条KV记录,规则如下
1 | Key:table_name.primary_key_column_values.non_primary_key_column_name |
对于主键列,只需要用一个特殊的列名,标识其存在即可,F1使用了列名为exists,列值为null。
下面举一个例子来说明上述映射规则
1 | create table Example |
假设其中插入了两行数据
1 | first_name last_name age phone_number |
按照上述规则转换成的KV记录为
1 | Key Value |
在关系型数据库中,除了数据表本身之外,还有索引表,F1中索引表的存储格式为
1 | Key:table_name.index_name.index_column_values.primary_column_values |
在索引表对应Key中存储主键列的值一方面是为了避免Key重复,另一方面是为了查询时能够做回表操作。接着上面的例子,假设在Example表格中,建了一个索引index_age,如下
1 | create index index_age on Example(age); |
那么,索引表中的两行对应的KV记录如下
1 | Key Value |
除了将关系性Schema中的行映射成KV记录外,F1 Server还负责将关系操作映射对应的KV操作,通常的关系操作包括insert、delete、update和select。
- insert:插入会指定各列的值,根据Schema的行映射关系,生成对应的KV记录,将记录写入到KV存储中;
- delete:先通过用户请求或者get接口确定要删除的所有Key,然后删除对应的KV记录,需要KV存储引起提供的get和del接口;
- update:先通过用户请求或者get接口确定要更新的所有Key,如果是非主键列更新,则调用put接口,如果是主键列更新,则是del和put接口;
- select:通过get接口查询到匹配的KV记录,并映射成关系型Schema中的行;
Schema变更带来的问题
根据F1的架构特点,事务执行时,有可能出现不同的语句在不同的F1 Server执行的情况,那么不同的语句可能使用了不同版本的关系型Schema。为了设计和实现简单,F1只允许系统中同时出现两种不同版本的Schema,如下
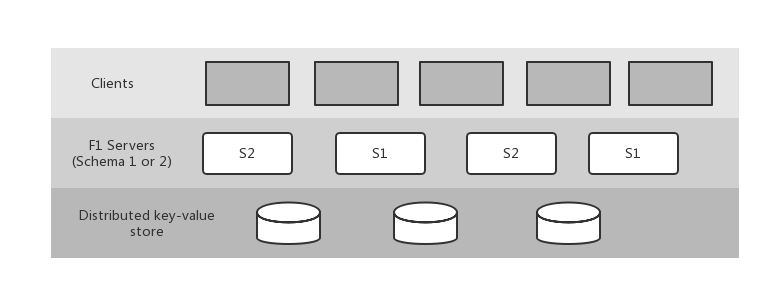
假设Schema版本S1 < S2,且S2比S1多了一张索引表,有如下执行过程
- 在S2版本的F1 Server上执行insert语句,由于S2版本包括索引表,因此会生成索引表相关的KV记录;
- 在S1版本的F1 Server上执行delete语句,且和1中insert语句使用相同的主键,由于S1版本不包括索引表,因此索引表相关的KV记录不会被删除;
当上述事务执行完成后,索引表将会有多余的中间数据,导致数据表和索引表的数据不一致。
F1 Schema变更算法
F1 Schema变更算法要解决的问题是在系统中至多允许存在两个版本的Schema的前提下,保证数据库的表示(即所有的记录集合)在Schema变更时保持一致性。在讨论如何解决该问题之前,还需要定义清楚,何为数据库表示的一致性?在F1中,Schema的最终状态分为两种absent和public,一个数据库表示在某个版本的Schema S上是一致的,其需要满足如下条件:
- 列值记录存在,则数据库表示中一定有包含它的行和表;
- 每行的public状态的列都有对应的列值;
- 所有的索引记录,其索引表在Schema S中一定存在;
- 所有public的索引包含其主表所有的行对应的索引记录;
- 所有的索引记录都会指向主表中合法的记录;
- 所有的public约束都会被严格遵守;
- 没有未知的值;
如果数据库中包含了本不应该属于它的数据,此不一致称为orphan data anomaly,即违反了1,3,5,7约束项;如果数据库缺少了本应该属于它的数据,或者违反了一个public约束,此不一致称为integrity anomaly,即违反了2,4,6约束项。
假设OP(S),代表任意的delete,update,insert或select在特定的Schema S中执行,任意一个正确实现的操作,应该保证该操作在Schema S中执行后,数据库表示是一致的,但是它不能保证按照Schema S版本执行之后,数据库表示还能在其他版本的Schema S’中也是一致的。
因此,Schema变更前后(S1->S2)的数据库表示一致性的,需要满足如下条件
- 任意的OP(S1)需要在Schema版本S1应用后,数据库表示在Schema版本S2上是一致的;
- 任意的OP(S2)需要在Schema版本S2应用后,数据库表示在Schema坂本S1上是一致的;
从前文的分析知道,直接将Schema元素从absent->public是可能导致数据库表示不一致的,因此,F1引入了Schema变更的中间状态,包括delete-only,write-only和write-only constraint。
- delete-only:一个delete-only状态的表,列和索引,不能被select,并且满足如下条件
- 对于表或列,只能被delete修改
- 对于索引,只能被delete和update修改
write-only:一个write-only的列或者索引,可以做insert,delete和update操作,但不能做select操作
write-only constraint:write-only constraint只能应用于新的insert,delete和update的数据,但对已有的数据不保证约束条件是满足的
添加/删除 Optional的Schema元素
从前面Schema变更的问题可以看出,Schema版本的回退导致在新版本插入的数据,回退到老版本时无法删除,因此,直观上来讲,对于添加一个Optional的Schema元素,可以在absent->public中间插入一个delete-only状态,即absent->delete-only->public,接下来将说明这样的变更过程是安全的。
首先来看absent->delete-only,由于两种状态都不会产生新的Schema元素的数据,因此,保证了不会出现orphan data问题,并且由于两种状态都是非public状态,因此,不会出现integrity问题。
接着来看delete-only->public,由于两种状态都能够删除需要删除的数据,因此,不会出现orphan data问题,且由于Schema元素是Optional的,因此,不会出现integrity问题。
删除的变更过程正好相反,不再描述,下文同。
添加/删除 Required的Schema元素
添加Required的Schema元素不能直接采用absent->delete-only->public的变更流程,因为,添加Required的Schema元素需要补充已有的数据,而delete-only状态是无法补充数据的,因此,需要在delete-only->public中添加一个write-only状态,即添加一个Required的Schema元素需要经过absent->delete-only->write-only->public的变更流程,接下来就来说明这个变更过程是能保证数据的一致性的。
absent->delete-only状态前面已描述过,这里不再赘述。对于delete-only->write-only状态转换,由于两种状态下都会删除新添加的Schema元素相关联的数据,因此不会出现orphan data问题,并且,由于两种Schema状态都是非public的,能保证不会出现integrity问题。
write-only->public的状态变化过程中,需要先保证对已有的数据完成补充,才能最终将状态变成public,由于两种状态都能删除新添加的Schema相关的数据,因此,不会出现orphan data问题,并且,由于两种Schema状态都会对新写入的数据做约束检查,新数据是能保证约束的,而对于原有的数据,需要后台任务在填充时做检查,如果都满足条件,才能将Schema元素变成public,否则,Schema变更应该失败。
实现限制点
由于F1 Server只允许同时存在两个不同版本的Schema,因此,在实现时,需要通过Schema Lease来保证Schema的更新,如果一个F1 Server无法更新Lease,那么会自动退出。同时,F1 Server的写操作不能跨两个版本的Schema,因此,如果一个写操作是基于老版本Schema的,是无法成功的,需要重试。
另外,由于同时只允许存在两个不同版本的Schema,因此,1个Schema Lease只能做一个中间状态的变更,通常的不带数据不全的DDL操作,需要等待3-4个Schema Lease,而Schema Lease是分钟级别的,因此,一个不带数据不全的DDL变更需要等待分钟到数十分钟;如果带上数据补全,则根据原有数据量的大小,耗费的时间可能会很长。F1中采用把多个DDL变更的中间批量执行,来提高Schema变更的效率。
最后,博客推送的公众号欢迎大家关注