介绍
本篇文章主要描述了如何使用golang实现一个单机版的MapReduce程序,想法来自于MIT-6.824课程的一个lab。本文分为以下几个模块:
- MapReduce基本原理
- MapReduce简单使用
- MapReduce单机版实现
MapReduce基本原理
MapReduce的计算以一组Key/Value对为输入,然后输出一组Key/Value对,用户通过编写Map和Reduce函数来控制处理逻辑。
Map函数把输入转换成一组中间的Key/Value对,MapReduce library会把所有Key的中间结果传递给Reduce函数处理。
Reduce函数接收Key和其对应的一组Value,它的作用就是聚合这些Value,产生最终的结果。Reduce的输入是以迭代器的方式输入,使得MapReduce可以处理数据量比内存大的情况。
一次MapReduce的处理过程如下图:
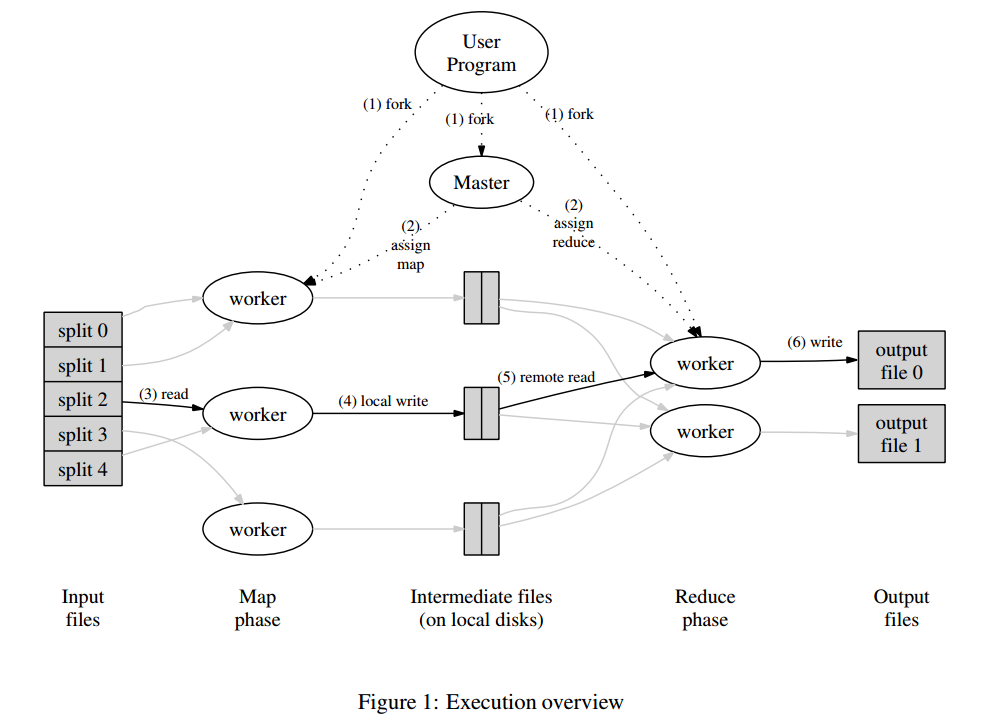
- MapReduce library会把输入文件划分成多个16到64MB大小的分片(大小可以通过参数调节),然后在一组机器上启动程序。
- 其中比较特殊的程序是master,剩下的由master分配任务的程序叫worker。总共有M个map任务和R个reduce任务需要分配,master会选取空闲的worker,然后分配一个map任务或者reduce任务。
- 处理map任务的worker会从输入分片读入数据,解析出输入数据的K/V对,然后传递给Map函数,生成的K/V中间结果会缓存在内存中。
- map任务的中间结果会被周期性地写入到磁盘中,以partition函数来分成R个部分。R个部分的磁盘地址会推送到master,然后由它转发给响应的reduce worker。
- 当reduce worker接收到master发送的地址信息时,它会通过RPC来向map worker读取对应的数据。当reduce worker读取到了所有的数据,它先按照key来排序,方便聚合操作。
- reduce worker遍历排序好的中间结果,对于相同的key,把其所有数据传入到Reduce函数进行处理,生成最终的结果会被追加到结果文件中。
- 当所有的map和reduce任务都完成时,master会唤醒用户程序,然后返回到用户程序空间执行用户代码。
成功执行后,输出结果在R个文件中,通常,用户不需要合并这R个文件,因为,可以把它们作为新的MapReduce处理逻辑的输入数据,或者其它分布式应用的输入数据。
更详细的介绍可以参考我之前写的博客MapReduce原理
MapReduce核心组件
MapReduce核心组件包括Master和Worker,它们的职责分别如下。
Master
MapReduce负责一次执行过程中Map和Reduce任务的调度,其需要维护的信息包括如下:
- worker的状态
- 任务的状态
- Map生成的文件的位置
Worker
Worker分为两种,分别是Map和Reduce:
Map Worker的职责:
- 对分片数据调用用户指定的Map函数
- 根据Reduce的个数,把数据分成R份
Reduce Worker的职责:
- 对收集到的数据进行排序
- 对于相同的Key调用Reduce函数进行处理
MapReduce简单使用
了解MapReduce基本原理后,再来通过一个简单的word count例子,来描述MapReduce的使用方法,代码如下:
1 | // The mapping function is called once for each piece of the input. |
一个MapReduce程序由三个部分组成:
- Map函数
- Reduce函数
- 调用MapReduce执行的函数
Map函数
Map函数主要的功能为吐出K/V对
Reduce函数
Reduce函数则是对相同的Key做操作,一般是统计之类的功能,具体地看应用的需求。
调用MapReduce库函数
分为Sequential和Distributed,其中Sequential为串行地执行Map和Reduce任务,主要用于用户程序调试的场景,Distributed则用于真正的用户程序执行的场景。
MapReduce单机版实现
本节实现的MapReduce单机版与Google论文中的MapReduce主要的不同如下:
- 输入和输出数据都采用本机的文件系统,没有使用到类似于GFS的分布式文件存储
- Google的MapReduce通过GFS的文件名字的原子操作来保证Reduce Worker宕机时,最终只会生成一份结果文件;在单机文件系统中,如果Worker和Master之间网络通信断掉,但是Worker本身可能还在工作,这时候如果重新启动另一个Worker可能会造成两个Worker写入同一份文件,这种场景,在单机版MapReduce的Worker容灾中不考虑。
本节分为两个部分来讨论:
- MapReduce的Sequential实现
- MapReduce的Distributed实现(带Worker容灾)
MapReduce的Sequential实现
Sequential部分的调度程序实现如下:
1 | // Sequential runs map and reduce tasks sequentially, waiting for each task to // complete before scheduling the next. |
其逻辑非常简单,就是按照顺序先一个个的处理Map任务,处理完成之后,再一个个的处理Reduce任务。
接下来,看doMap和doReduce是如何实现的。
doMap的实现如下:
1 |
|
处理过程如下:
- 读入输出文件
- 调用用户指定的Map函数,吐出所有的K/V对
- 创建跟Reduce Worker相同数量的文件,然后,对每个K/V对,根据Key来做hash,输出到对应的文件
doReduce实现如下:
1 | // doReduce does the job of a reduce worker: it reads the intermediate |
Reduce任务的处理逻辑如下:
- 根据之前约定好的命名格式,找到该Reduce Worker需要处理的文件,然后,按照约定的方式进行解码
- 得到所有的K/V对之后,根据Key对K/V对排序
- 调用用户指定的ReduceF函数,对相同的Key的所有Value进行处理
- 把处理后的结果以一定的编码方式写入文件
MapReduce的Distributed实现(带Worker容灾)
Distributed和Sequencial的主要区别在于调度函数的实现,如下
1 | // schedule starts and waits for all tasks in the given phase (Map or Reduce). |
分为Map和Reduce两阶段的调度,先来看ScheduleMap部分:
ScheduleMap
1 | type taskStat struct { |
- 先根据已注册的Worker数量,生成相应数量的Map任务,然后发送给Worker执行
- 接下来在,在select中处理两种事件:一是有新Worker注册的事件;二是之前调度的任务执行完成的事件
不带Worker容灾的处理:
处理新Worker注册的事件的方式为选择下一个要执行的任务,发送给新注册的Worker去执行。
处理调度完成的事件的方式为选择下个需要执行的任务,调度给刚刚完成执行任务的Worker执行。当所有的Map任务都处理完成后,表示Map阶段完成,退出调度。
带Worker容灾的处理:
Worker容灾的处理逻辑为,当任务执行失败时,加入到执行失败的任务队列中,当发生上述两种事件时,先从失败的任务队列中拿下一个任务执行,只有当失败的任务队列为空时,才调度新的任务执行。
ScheduleReduce
ScheduleReduce的实现如下
1 | func (mr *Master) scheduleReduce() { |
整体的处理逻辑和ScheduleMap类似,如下
- 先根据已注册的Worker数量,生成相应数量的Reduce任务,然后发送给Worker执行
- 接下来在,在select中处理两种事件:一是有新Worker注册的事件;二是之前调度的任务执行完成的事件
容灾过程也是类似的,不再赘述。
博客中用到的程序放在链接中,有需要的同学自取。
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。
