Introduction
本文收录在paper项目中,papers项目旨在学习和总结分布式系统相关的论文;同时本文也是DSTORE项目的必备知识,DSTORE的目标是自己动手实现一个分布式KV存储引擎。
本文为raft系列文章第一篇,本系列其他文章为
- raft原理(二):安全性和集群成员变更
- raft原理(三):日志合并及客户端交互
- golang实现raft(一):选举和日志同步
- golang实现raft(二):集群成员变更
本文介绍了分布式一致性算法raft的选主和日志复制原理,raft算法的主要目标是为了让分布式一致性算法更易理解和用于工程实践。
raft算法的主要特性为
- strong leader:raft算法使用的是strong leader方式,日志只能从leader同步到follower
- leader election:使用随机定时器来选主
- Membership changes:采用的是两阶段更新配置信息的方式
本文的组织结构如下
- Replicated state machines
- Strenthens and weaks of Paxos
- Understandability
- Raft basics
- Raft leader election
- Raft log replication
Replicated State Machine
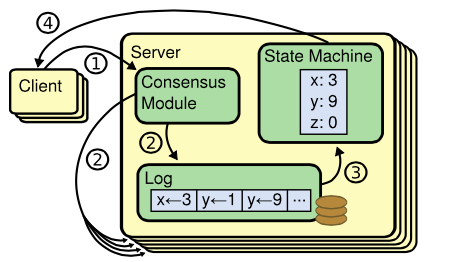
Repicated State Machine一般分为三个部分:
- Log:记录一系列的指令
- State Machine:把日志中提交的指令回放到状态机中
- Consensus Module:分布式环境下,保证多机的日志是一致的,这样回放到状态机中的状态是一致的
一致性算法作用于Consensus Module,一般有以下特性:
- safety:在非拜占庭问题下(网络延时,网络分区,丢包,重复发包以及包乱序等),结果是正确的
- availability:在半数以上机器能正常工作时,则系统可用
- timing-unindependent:不依赖于时钟来保证日志一致性,错误的时钟以及极端的消息时延最多会造成可用性问题
What’s wrong with Paxos?
Paxos算法存在的主要问题为
- 难以理解:对于大部分人来讲,难以理解Paxos论文
- 难以实现:Paxos算法在工程上实现难度高,论文中缺少必要的细节,并且整个Paxos的算法的思想决定了其不易于实现
Understandability
鉴于Paxos难以理解和实现,raft的首要目标是使其易于理解,为此raft采用了以下设计思想来达到此目标:
- decomposition:把整个算法分为election,log replication,safety and membership changes
- Simplify the state space:例如,日志不允许有空洞等等
Raft basics
Raft通过选出一个leader来简化日志副本的管理,例如,日志项(log entry)只允许从leader流向follower。
基于leader的方法,Raft算法可以分解成三个子问题:
- Leader election:原来的leader挂掉后,必须选出一个新的leader
- Log replication:leader从客户端接收日志,并复制到整个集群中
- Safety:如果有任意的server将日志项回放到状态机中了,那么其他的server只会回放相同的日志项
Raft Server States
一个Raft集群通常有几台Raft Server组成,每个Server处于以下三种状态之一:
- leader:处理所有的客户端请求
- follower:响应来自leader和candidate的请求
- candidate:用于选主
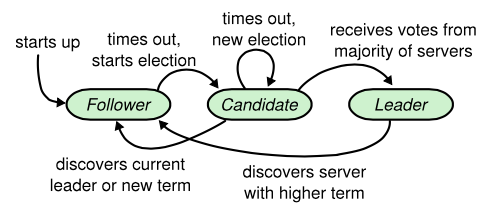
Raft Server State Transformation
Raft可能的状态变化如下图:
Raft将时间分为多个term,term以连续的整数来标识,每个term以一次election开始,如果有server被选为leader,则该term的剩余时间该server都是leader。
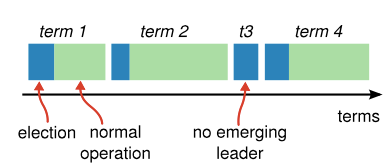
有些term里,可能并没有选出leader,这时候会开启一个新term来继续选主,如上图中的t3。
每个server都维护着一个当前term(current term),有可能会存在某些server整个term都没参与的情况,这时候,在server通信的时候,会带上彼此的当前term信息,server会更新成它们之间的较大值。当leader或candidate发现它们的term属于老的值时,它们会转成follower状态。
Raft Server之间的通信通过RPC来进行,基础的raft算法只需要实现RequestVote和AppendEntries两个RPC。
Raft Leader Election
Raft使用心跳来触发选主,当server启动时,状态是follower。当server从leader或者candidate接收到合法的RPC时,它会保持在follower状态。leader会发送周期性的心跳来表明自己是leader。
当一个follower在election timeout时间内没有接收到通信,那么它会开始选主。
选主的步骤如下:
- 增加current term
- 转成candidate状态
- 选自己为主,然后把选主RPC并行地发送给其他的server
- candidate状态会继续保持,直到下述三种情况出现
candidate会在下述三种情况下退出
- server本身成为leader
- 其他的server选为leader
- 一段时间后,没有server成为leader
server本身被选为leader
当server得到集群中大多数的server的选举后,它会成为leader。对于每个server来讲,只能选举一台server为leader,从而使得大多数原则能确保只有一个candidate会被选成leader。
当candidate成为leader后,会发送心跳信息告诉其他server,从而防止新的选举。
其他server选为leader
如果在等待选举期间,candidate接收到其他server要成为leader的RPC,分两种情况处理:
- 如果leader的term大于或等于自身的term,那么改candidate会转成follower状态
- 如果leader的term小于自身的term,那么会拒绝该leader,并继续保持candidate状态
一段时间后,没有server成为leader
有可能,很多follower同时变成candidate,导致没有candidate能获得大多数的选举,从而导致无法选出主。当这个情况发生时,每个candidate会超时,然后重新发增加term,发起新一轮选举RPC。需要注意的是,如果没有特别处理,可能出导致无限地重复选主的情况。
Raft采用随机定时器的方法来避免上述情况,每个candidate选择一个时间间隔内的随机值,例如150-300ms,采用这种机制,一般只有一个server会进入candidate状态,然后获得大多数server的选举,最后成为主。每个candidate在收到leader的心跳信息后会重启定时器,从而避免在leader正常工作时,会发生选举的情况。
Raft Log replication
当选出leader后,它会开始接受客户端请求,每个请求会带有一个指令,可以被回放到状态机中。leader把指令追加成一个log entry,然后通过AppendEntries RPC并行的发送给其他的server,当改entry被多数派server复制后,leader会把该entry回放到状态机中,然后把结果返回给客户端。
当follower宕机或者运行较慢时,leader会无限地重发AppendEntries给这些follower,直到所有的follower都复制了该log entry。
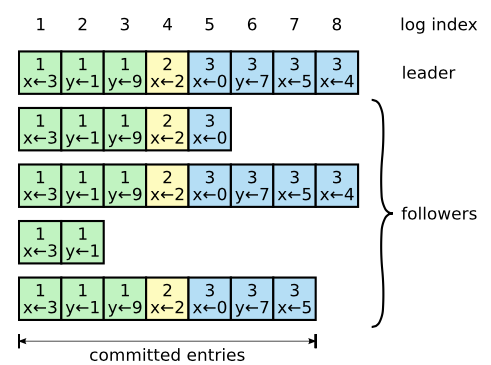
log按照上图方式组织,每个log entry存储了指令和term信息,由leader指定。每个log entry有个数字索引(index)来表名其在log中的位置。
leader决定什么时候将一个log entry回放到状态机中是安全的,被回放的log entry称为committed,raft保证所有committed log entry会被持久化,并且最终会被回放到所有可工作的状态机中。
一个log在大多数的server已经复制它之后,则是committed(这个特指在leader的term里面的日志),在复制该log的同时,同时也会告诉已复制该log entry的follower,其之前的log entry也被提交了,follower则可以回放其之前的log entry。例如上图中的entry 7。leader会维护最大的committed的entry的index,当一个follower发现log entry已提交,则会将它回放到状态机中。
raft的log replication保证以下性质(Log Matching Property):
- 如果两个log entry有相同的index和term,那么它们存储相同的指令
- 如果两个log entry在两份不同的日志中,并且有相同的index和term,那么它们之前的log entry是完全相同的
其中特性一通过以下保证:
- leader在一个特定的term和index下,只会创建一个log entry
- log entry不会改变它们在日志中的位置
特性二通过以下保证:
AppendEntries会做log entry的一致性检查,当发送一个AppendEntriesRPC时,leader会带上需要复制的log entry前一个log entry的(index, iterm)
- 如果follower没有发现与它一样的log entry,那么它会拒绝接受新的log entry
这样就能保证特性二得以满足。
在正常情况下,leader和follower会保持一致,一致性检查通常都会成功。但是,当leader崩溃后,可能会出现日志不一致的情况,通过一个例子来说明。
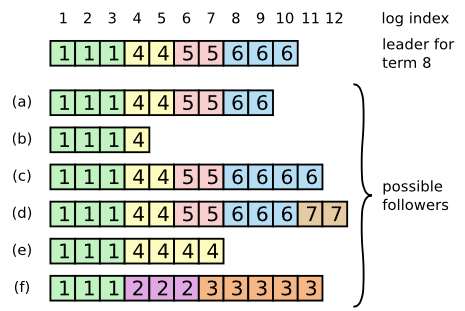
如上图所示,raft的leader强制以自己的日志来复制不一致的日志,通过以下方法:
- 找到leader和follower最后一个相同的log entry,然后删掉follower后面的日志,然后把该log entry之后的leader日志复制给follower
上述方法是通过AppendEntries的一致性检查实现的,如下:
- leader为每个follower维护一个nextIndex,表明下一个将要发送给follower的log entry
- 当leader刚上任时,会把所有的nextIndex设置成其最后一个log entry的index加1,如上图,则是11
- 当follower的日志和leader不一致时,一致性检查会失败,那么会把nextIndex减1
- 最终nextIndex会是leader和follower相同log entry的index加1,这时候,再发送
AppendEntries会成功,并且会把follower的所有之后不一致的日志删除掉
优化
上述一次回退一个log entry的方法效率较低,在发生冲突时,可以让follower把冲突的term的第一个日志的index发回给leader,这样leader就可以一次过滤掉该term的所有log entry。
在正常情况下,log entry可以通过一轮RPC就能将日志复制到大多数的server,少数的慢follower不会影响性能。
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。
