Introduction
本文收录在paper项目中,papers项目旨在学习和总结分布式系统相关的论文;同时本文也是DSTORE项目的必备知识,DSTORE的目标是自己动手实现一个分布式KV存储引擎。
本文为raft系列文章第二篇,本系列其他文章为
- raft原理(一):选举和日志复制
- raft原理(三):日志合并及客户端交互
- golang实现raft(一):选举和日志同步
- golang实现raft(二):集群成员变更
本文将继续讨论raft原理,包括raft的安全性和集群成员变更,全文组织结构如下
- Safety
- Cluster Membership Changes
Safety
前面描述了raft是如何选主和复制日志的,但是没有讨论raft是如何保证所有server的状态机按照相同的顺序执行完全相同的指令的。本节将在server被选为主的限制进行补充,保证了任何term被选为leader都会包含前面所有提交过的log entry,具体地将会通过本节描述的一系列规则来阐述。
Election Restriction
在一些一致性算法中,即使一台server没有包含所有之前已提交的log entry,也能被选为主,这些算法需要把leader上缺失的日志从其他的server拷贝到leader上,这种方法会导致额外的复杂度。相对而言,raft使用一种更简单的方法,即它保证所有已提交的log entry都会在当前选举的leader上,因此,在raft算法中,日志只会从leader流向follower。
为了实现上述目标,raft在选举中会保证,一个candidate只有得到大多数的server的选票之后,才能被选为主。得到大多数的选票表明,选举它的server中至少有一个server是拥有所有已经提交的log entry的,而leader的日志至少和follower的一样新,这样就保证了leader肯定有所有已提交的log entry。
Committing entries from previous terms
从日志复制一节可以知道,在当前term,一个leader知道一个log entry在复制到大多数server后,其就可以被提交了。当一个leader在提交log entry之前宕机掉,后面选举出来的leader会复制该log entry,但是,一个leader不能立马对之前term的log entry是否复制到大多数server来判断其是否已被提交。
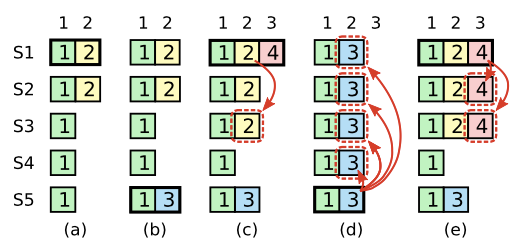
如上图的例子,图(c)就发生了一个log entry虽然已经复制到大多数的server,但是仍然有可能被覆盖掉的可能,如图(d),整个发生的时序如下:
- 图a中,S1被选为主,然后复制到log index为2的log entry到S2上
- 图b中,S1挂掉,然后S5获得了S3,S4和自身的选举,成为leader,然后,其从客户端收到了一个新的log entry(3)
- 图c中,S5挂掉,S1重新正常工作,又被选为主,继续复制log entry(2),在log entry(2)被提交前,S1又挂掉
- 图d中,S5又重新被选为leader,然后,会把term 3的log entry覆盖到其他log index为2的log entry
因此,在raft中,不会通过日志复制的个数来提交之前term的log entry,只有当前term的log entry才会通过日志副本的个数来判断,例如,图e中,如果S1在挂掉前把log entry(4)复制到了大多数的server后,就能保证之前的log entry(2)被提交了,之后S5也就不可能被选为leader了。
Safety argument
本小节将证明已经被leader提交的log entry,在之后选举出的leader中也会存在。
以反证法来证明,假设Term T的leader T提交了一个log entry,但是此log entry没有在之后的某些term中,不妨设最小的Term U的leader U中不存在此log entry。证明如下:
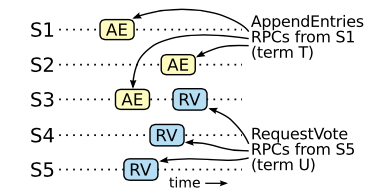
- 提交的log entry在leader U被选为主之前已经不存在了,因为leader不会删除或覆盖自己之前的log entry;
- leader T复制该log entry到大多数的server上,并且leader U获得了大多数server的选举,因此,至少有一个server(称为voter)同时复制了该log entry,并且选举U为leader,例如上图中的S3就是这样的server;
- voter在选举leader U之前,从leader T获得了此log entry,因为U > T,如果先选举leader U的话,则S1在term T发送给它的
AppendEntriesRPC会失败; - voter在选举leader U的时候,还存储着此log entry,因为,假设中U是最小的不存在此log entry的leader,且[T,U)之间的leader不会删除和覆盖自己的log entry且follower只会删除和leader冲突的log entry;
- voter选举U为leader,说明U的日志至少是和voter一样新的,这点导致两点假设不成立;
- 第一,如果voter和U的最后的term相同,那么leader U则至少在最后的term的日志和voter的一样长,即包含了leader T提交的log entry;
- 第二,如果voter和U的最后的term不相同,那么U的必定大于voter的,则leader U必须包含term T的所有日志,因为U > T;
- 因此,假设不成立,不可能存在term U,使得term U中的leader不包含之前leader已经提交过的log entry。
Follower and candidate crashes
follower崩溃掉后,会按如下处理
- leader会不断给它发送选举和追加日志的RPC,直到成功
- follower会忽略它已经处理过的追加日志的RPC
Time and availability
在raft中,election timeout的值需要满足如下条件:
1 | broadcastTime << electionTimeout << MTBF |
其中broadcastTimeout是server并行发送给其他server RPC并收到回复的时间;electionTimeout是选举超时时间;MTBF是一台server两次故障的间隔时间。
electionTimeout要大于broadcastTimeout的原因是,防止follower因为还没收到leader的心跳,而重新选主。
electionTimeout要小于MTBF的原因是,防止选举时,能正常工作的server没有达到大多数。
对于boradcastTimeout,一般在[0.5ms,20ms]之间,而MTBF一般非常大,至少是按照月为单位。因此,一般electionTimeout一般选择范围为[10ms,500ms]。因此,当leader挂掉后,能在较短时间内重新选主。
Cluster Membership Changes
在集群server发生变化时,不能一次性的把所有的server配置信息从老的替换为新的,因为,每台server的替换进度是不一样的,可能会导致出现双主的情况,如下图:
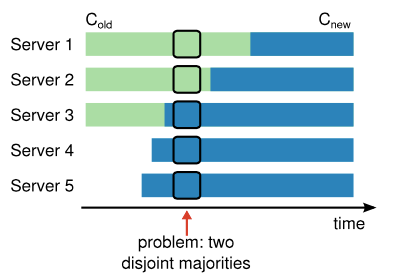
如上图,Server 1和Server 2可能以Cold配置选出一个主,而Server 3,Server 4和Server 5可能以Cnew选出另外一个主,导致出现双主。
raft使用两阶段的过程来完成上述转换:
- 第一阶段,新老配置都存在,称为joint consensus
- 第二阶段,替换成新配置
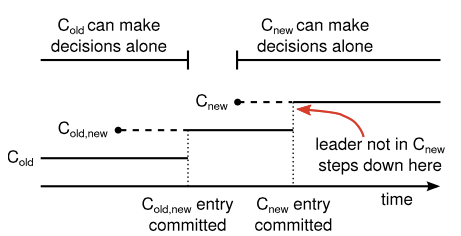
- leader首先创建Cold,new的log entry,然后提交(保证大多数的old和大多数的new都接收到该log entry);
- leader创建Cnew的log entry,然后提交,保证大多数的new都接收到了该log entry。
这个过程中,有几个问题需要考虑。
- 新加入的server一开始没有存储任何的log entry,当它们加入到集群中,可能有很长一段时间在追加日志的过程中,导致配置变更的log entry一直无法提交
Raft为此新增了一个阶段,此阶段新的server不作为选举的server,但是会从leader接受日志,当新加的server追上leader时,才开始做配置变更。
- 原来的主可能不在新的配置中
在这种场景下,原来的主在提交了Cnew log entry(计算日志副本个数时,不包含自己)后,会变成follower状态。
- 移除的server可能会干扰新的集群
移除的server不会受到新的leader的心跳,从而导致它们election timeout,然后重新开始选举,这会导致新的leader变成follower状态。Raft的解决方案是,当一台server接收到选举RPC时,如果此次接收到的时间跟leader发的心跳的时间间隔不超过最小的electionTimeout,则会拒绝掉此次选举。这个不会影响正常的选举过程,因为,每个server会在最小electionTimeout后发起选举,而可以避免老的server的干扰。
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。
