Introduction
本文为学习The go programming language的总结笔记,主要分为
- Functions
- Methods
- Interfaces
Functions
Function Declarations
GO函数声明的语法如下
1 | func name(parameter-list) (result-list) { |
在GO中,返回值是可以命名的,这样函数初始化时会为每个命名的返回值初始化一个zero value。
在GO中,有返回值的函数,必须在结束的时候有一个return语句。
以下函数声明是相同的
1 | func f(i, j, k int, s, t string) |
GO函数是值传递的,函数内部对函数参数的修改,一般不会影响原始的变量值,除了传入的是引用类型,例如pointer、slice、map、function或channel。
Recursion
GO函数是支持递归调用,本节通过一个HTML解析程序来说明。
本节使用golang.org/x/net/html包,其中html.Parse会返回一系列的HTML的元素,例如text,comment等等,但是,我们这个程序只关注<name key='value'>形式的元素。
1 | package main |
其中visit函数递归的调用自身,来完成对HTML元素的子元素的遍历。
Multiple Return Values
GO中,支持函数有多个返回值,一般,一个返回值是结果,另外一个是标明错误情况等。
1 | package main |
上述代码中,findLinks包含了html处理过程中的错误情况,方便调用者知道函数调用过程中是否发生错误,错误类型是什么。
前面提到GO支持命名的返回值,如下
1 | func CountWordsAndImages(url string) (words, images int, err error) |
如上所示,返回值的命名的,所以空的return语句等同于return words, images, err
Errors
通常,在GO中,如果函数需要处理异常情况,会增加一个返回值err,来表示函数出错的原因。内置的error是一个interface类型,当返回的err为nil时,则表示执行成功,否则表示执行出错,可以用fmt.Println(err)来输出错误的信息。
大部分情况下,如果err不为nil,则函数的其他返回值是无效值,不过,有些函数的部分返回值可能是有效的,例如,Read函数可能会返回它能够读到的字节数,对于这种函数,编写者应该清晰地在文档中注明这种情况。
Error-Handling Strategies
当一个函数返回错误,调用者必须能够采取正确的行为来处理不同的错误,一般分为5种情况:
传播错误
一种比较常见的方法是传播错误到当前函数的上一层,由上层来处理具体地错误。在findLinks函数中,有如下代码
1 | resp, err := http.Get(url) |
除了上面的直接传播错误之外,还有经过稍微整合之后的传播,如下
1 | doc, err := html.Parse(resp.Body) |
这里把出错的URL封装到err中一起传递给上层调用者。
重试
第二种处理错误的方式是重试,对于可能是暂时的问题(例如网络问题),可以通过重试几次或一段时间,直到成功或者最终失败。
1 | func WaitForServer(url string) error { |
不可能的错误—打印错误,优雅地终止程序
这种错误处理方式只适用于main package,对于普通的library package,只允许传播错误。
1 | if err := WaitForServer(url); err != nil { |
可以用log.Fatalf来完成上述功能
1 | if err := WaitForServer(url); err != nil { |
打印出错误,继续以不完全功能执行
有时候,可以打印出错误,然后继续以不完全功能执行
1 | if err := Ping(); err != nil { |
上述程序打印出网络问题,然后在没网的条件下继续执行。
完全忽略错误
少数情况下,我们可以完全地忽略错误。
1 | dir, err := ioutil.TempDir("", "scratch") |
最后的os.RemoveAll(dir)可能会出错,但是操作系统可以定期地清理临时文件夹,因此,这种情况下可以忽略错误,但是,如果要确定要忽略错误,则需要在代码中表明这样做的用意。
End of File(EOF)
在文件IO中,一般EOF并不是一种错误,只是代表文件中的数据已经读完了。对于EOF,调用者一般需要做特殊的处理。
1 | in := bufio.NewReader(os.Stdin) |
Function Values
在GO中,函数也能是值类型赋值给其他的变量,例如
1 | func square(n int) int |
函数的zero value是nil,调用nil的函数会panic
1 | var f func(int) int |
函数可以作为另一个函数的参数,从而可以方便的自定义一些行为,例如
1 | func add1(r rune) rune {return r + 1} |
Anonymous Functions
匿名函数和普通函数类似,除了它在func之后不带名字,例如
1 | strings.Map(func (r rune) rune {return r + 1}, "HAL-9000") |
另外,匿名函数是有状态的,如下
1 | func squares() func() int { |
可以看出,x的值看起来是被保存下来,每次都是在上次的基础上加1,这种类型的function value,也称为闭包。
Caveat: Capturing Iteration Variables
本节通过一个例子来说明
1 | var rmdirs []func() |
上面为什么需要用dir: = d赋值语句了,直接把dir传进MkdirAll不就好了吗?
在上面的代码中,for循环创建了一个新的作用域,其中dir被声明了,所有的在这个循环内的function value都会共享同一份dir的存储空间,因此,如果不采用上述代码,那么,传进function value的dir就会全部是一样的。
下面的代码也会有上述问题
1 | var rmdirs []func() |
其中,i的值也是循环内部所有function value共享的,导致最终i都是等于len(dirs) - 1。
Variadic Functions
可变参数函数指的是函数的参数是可变的,像fmt.Printf那种。
1 | func sum(vals ...int) int { |
上述调用会隐式地创建一个array,然后传递整个array对应的slice进入函数。
可变参数的函数和传递slice参数的函数还是不一样的,如下
1 | func f(...int) {} |
可变参数函数通常用来字符串格式化,例如
1 | func errorf(linenum int, format string, args ...interface{}) { |
Deferred Function Calls
defer语句的含义是函数和参数表达式会在语句执行的时候会被计算出来,但是函数真正的执行会在调用defer语句的函数结束后才会执行,包括函数的return语句,panic等。在一个函数中,可以有任意个defer语句,它们最终的执行是它们defer的相反顺序。
defer语句可以经常用来成对的操作,例如open和close,connect和disconnect,lock和unlock,可以保证资源会被释放。defer语句的正确的顺序为当一个资源被成功获取之后。
1 | func title(url string) error { |
defer语句也可以用来模拟”on entry”和”on exit”函数,如下
1 | func bigSlowOperation() { |
每次bigSlowOPeration被调用,它会打印entry和exit消息。
defer的匿名函数可以在函数返回前,修改返回值。
1 | func tuple(x int) (result int) { |
注意,defer的语句的最终调用是在函数结束的时候,有时候因为这个特性可能会出现问题
1 | for _, filename := range filenames { |
for循环中的所有文件不会马上被关闭,只有当函数退出时才会关闭,这可能会造成资源的浪费,可以修改如下
1 | for _, filename := range filenames { |
上述方法可以有效地解决这个问题,文件打开使用完后,马上就会被关闭。
Panic
GO的类型系统可以在编译期间检查很多错误,但是像数组的越界,空指针,需要在运行时做检查,当GO检测到这些错误的时候,它会panic。
一个典型的panic的包括以下流程,如下
- 正常的执行终止
- 所有defer的语句执行
- 打印panic消息,包括panic值,对每个goroutine,打印stack trace
内置的panic的函数也可以显式地被调用,它可以接受任意类型的参数。panic一般发生在一些不可能的场景的情况下,例如
1 | switch s := suit(drawCard()); s { |
由于GO的panic会导致程序终止,因此,一般用于不可恢复的错误。对于预期内的错误,采用一般的错误处理流程即可。
Recover
通常终止程序是处理panic的正确方式,但有时候也可以做一定程度的recover,例如,退出前清理,对于一个web服务器来讲,如果发生了非预期的错误,需要关闭链接,而不是让客户端hang住。
如果内置的recover函数被defer的函数调用,并且调用defer语句的函数panic了,那么recover函数会结束当前的panic状态,并且返回panic值。如果没有panic,recover函数不起任何作用,并且返回nil。
1 | func Parse(input string) (s *Syntax, err error) { |
在Parse中的defer函数从panic中recover,它使用recover返回的panic值来构建错误的消息。除了panic值之外,还有打印出runtime.Stack信息。
最好不要recover从别的package跑出来的panic,因为无法知道是否应该recover,也不很难知道应该以何种方式recover。
Methods
在GO中,实现面向对象编程的方法,即一个对象是指一个拥有method的值或变量,method指和指定类型关联的函数。
Method Declarations
method的定义比普通函数多了一个部分,即函数名前面有一个额外的参数,这个参数表明这个函数所属的类型。例如
1 | package geometry |
上面额外的参数p称为method receiver,在GO中不用使用特殊的this或self来命名method receiver,因为receiver的名称会被经常使用,因此,建议用短的变量名来定义它。
调用method和C++调用成员函数类似,通过对象名+ . + method名来调用,需要注意的是,普通的函数和method是可以有相同的名称的。
p.Distance称作是selector,因为,它会为找到对象p的合适的方法Distance;selector也用来访问struct类型的field,因此,对于struct类型,method和field的命名不能相同,否则会产生冲突。
每个类型都有自己的method namespace,因此,不同类型的type,可以定义同名的method,例如
1 | type Path []Point |
path是named slice类型,对于这种类型GO也支持定义method,实际上,在GO中,支持对任意的named type定义method。
在GO中,定义method的时候,不推荐再带上包的名字了,这样会比较累赘,例如
1 | import "gopl.io/ch6/geometry" |
对于path的method,推荐用Distance而不是PathDistance。
Methods with a Pointer Receiver
由于GO中,是以值传递的方式传函数参数的,如果希望method函数能够修改对象内部的状态的话,则需要定义receiver type为对象的指针,如下
1 | func (p *Point) ScaleBy(factor float64) { |
一般地,只要Point的任何method有pointer receiver,那么推荐其他method也定义一个pointer receiver。因为GO支持pointer receiver,因此,对本身是pointer类型的named type,不支持定义method。
1 | type P *int |
使用pointer receiver的方法如下
1 | r := &Point{1, 2} |
对于后两种用法,GO提供隐式地支持,即对于一个p,如果定义了*Point类型的receiver,GO会自动动在&p上调用该receiver,但这种支持仅限于变量,对于临时的值是不支持的,因为无法获得它们的地址。
1 | Point{1, 2}.ScaleBy(2) // compile error |
对于一个*Pointer类型的变量,GO也会隐式地调用Point.Distance函数,下面两种使用方式是等价的
1 | pptr.Distance(q) |
如上,采用第一种使用方式的时候,GO也会隐式地转成第二种使用方式。
如果对于一个named type T,它们所有的method的receiver都是T,而不是*T,那么拷贝是安全的,因为任意的method都会拷贝一份参数到函数中;但如果任意的method有pointer类型的receiver,那么拷贝是不安全的,例如,拷贝一份bytes.Buffer会造成它们共享底层的字节数组,如果同时使用这两个变量的话,可能会造成互相干扰。
Nil is a Valid Reciever Value
Nil是可以作为receiver值的,如下
1 | type IntList struct { |
Composing Types by Struct Embedding
和field一样,通过匿名的struct组合,大的struct可以直接调用struct内部的field的method,如下
1 | type Point struct {X, Y float64} |
上面的功能相当于编译器自动帮我们实现了以下代码
1 | func (p ColoredPoint) Distance(q Point) float64 { |
一个struct可以有多个匿名的field,因此,它们的method都会自动提升给大的struct
1 | type ColoredPoint { |
Point和color.RGBA的method都会自动提升给ColoredPoint。
Method Values and Expressions
通常的,我们在一个操作中select和call一个method,例如p.Distance(),但是,也可以把select和call分开。selector p.Distance会产生一个method value,一个method绑定到了特定的对象p,这个函数可以保存起来供后面重复使用。
1 | p := Point{1, 2} |
method value通常在你需要一个变量表示多个method value中的一个的时候,非常有用,例如
1 | type Point struct {X, Y float64} |
Example: Bit Vector Type
GO中没有set类型,虽然有时可以用map[T]bool来代替,但是,有时候bit set可以解决很多空间,如下
1 | package main |
Encapsulation
当客户端无法访问一个变量或方法时,我们称作对象的该方法和变量被封装了。GO只有一个控制访问的途径,即大写的是exported,因此,为了封装一个对象,我们可以把它设置成struct。
例如IntSet
1 | type IntSet struct { |
我们也可以直接定义IntSet成[]uint64,但这样客户端就可以直接修改IntSet内部的值了。
封装有三大好处
- 客户端不能直接修改内部的值,只需要调用几条语句就能完成复杂的功能
- 对客户端隐藏实现细节
- 防止客户端修改内部状态到非法的值
Interfaces
在Go中,interface为对一组函数的抽象,和其他语言不同的时,GO的接口是自动匹配的,只要一个类型有接口相应的method,那么这个类型就会自动成为接口。
本章中,我们先讨论interface的基础,然后介绍标准库的几个重要的接口,最后,我们讨论type assertions和type switches。
Interface as Contracts
在GO中,Interface是一种抽象类型,它不展示任何的内部的值,只提供一些method。因此,给定一个interface,你只知道它的几个method,对于内部的实现是无法知道的。
在本书中,我们用了像fmt.Printf和fmt.Sprintf等函数,这两个函数都是基于fmt.Fprintf实现的,如下
1 | package fmt |
上面io.Writer是interface类型,其定义如下
1 | package io |
Fprintf函数只要求它的第一个参数类型必须实现了Write函数,而具体是怎么实现的,Fprintf是不管的。我们可以自定义一个Writer来实现Write函数,如下
1 | type ByteCOunter int |
Fprintf会调用write函数,接着c中就会写入字母的个数,然后通过Println输出。
fmt package中还有一个很常见的interface,为fmt.Stringer,如下
1 | package fmt |
Interface Types
一个interface类型指定了一组method,一个具体的类型如果实现了interface里的所有方法,那么这个类型会自动地被认为是该interface的一个实例。
例如,Reader代表任何可以读数据的interface,而Closer则是任何可以关闭的值,例如网络链接等。
1 | package io |
也可以基于现有的interface组合出新的interface,例如
1 | type ReadWriter interface { |
上面的跟结构体的匿名field一样,method会自动地提升到大的interface中,如果不用匿名filed方式,则需要重新手写方法名,如下
1 | type ReadWriter interface { |
Interface Satisfication
当一个类型包含某个interface中所有的methods时,则该类型satisfies这个interface。例如,*os.File satisfies io.Reader,Writer和Closer。
在GO中,当这个类型satisfies这个interface时,则说具体的类型是某个interface,,因此*os.File是io.Reader,Writer和Closer。
对于interface,赋值的规则是当且仅当表达式是某个interface时,才能够进行赋值,例如
1 | var w io.Writer |
上述规则也适用于右边是本身也是interface的情况
1 |
|
在method一章中,我们知道当一个类型T的变量,是可以隐式地使用*T为receiver的method的,但临时的值是不行的,这可能会造成T类型比*T类型能satisfies较少的interface,如下
1 | type IntSet struct { |
由于IntSet本身没有string方法,且依赖自动地转换只能解决变量的问题,而临时的值无法转换,因此,IntSet不是Stringer类型的interface。
一个interface变量只能使用它本身所有的method,即使赋值给它的具体类型还有额外的method,也是无法调用的,例如
1 | os.Stdout.Write([]byte("hello")) |
空interface
inteface {}是一个空的interface,它的作用可以用来匹配任何的类型,例如
1 | var any interface {} |
为了从空interface中把类型信息取回来,我们需要用到type assertion技术,具体到本章后面会详细说明。
可以通过变量的定义,来静态的assert某个type是否是某个interface类型,如下
1 | var w io.Writer = new(bytes.Buffer) |
由于GO中是自动地将具体的类型匹配成interface的,因此,对于一些第三方的无法修改源码的库是比较有用的,我们只要定义好interface,第三方的类型会自动地匹配到。
Parsing Flags with flag.Value
本节主要以例子来说明,先来看传入时间作为命令行参数的例子。
1 | var period = flag.Duration("period", 1 * time.Second, "sleep period") |
上述代码中,period的默认值是1s,如果用户通过-period 时间传入值的话,flag.Parse()函数会解析出来,如下
1 | ./sleep |
因为Duration类型很重要,因此它们内置到flag package中。我们也可以自定义类型,只需要满足flag.Valueinterface即可,其定义如下
1 | package flag |
通过一个例子来说明如何自定义一个flag value,如下
1 | type celsiusFlag struct {Celsius} |
用法如下
1 | ./tempflag |
Interface Values
Interface value包含两个组件,分别是具体地类型和类型的值,它们被称作interface的dynamic type和dynamic value。
以一个简单的例子,来说明interface value,如下
1 | var w io.Writer |
对于语句1,创建了type和value都为nil的interface。
对于语句2,创建了type为*os.File,value为Os.Stdout的interface
对于语句3,创建了type为*bytes.Buffer,value为[]byte的interface
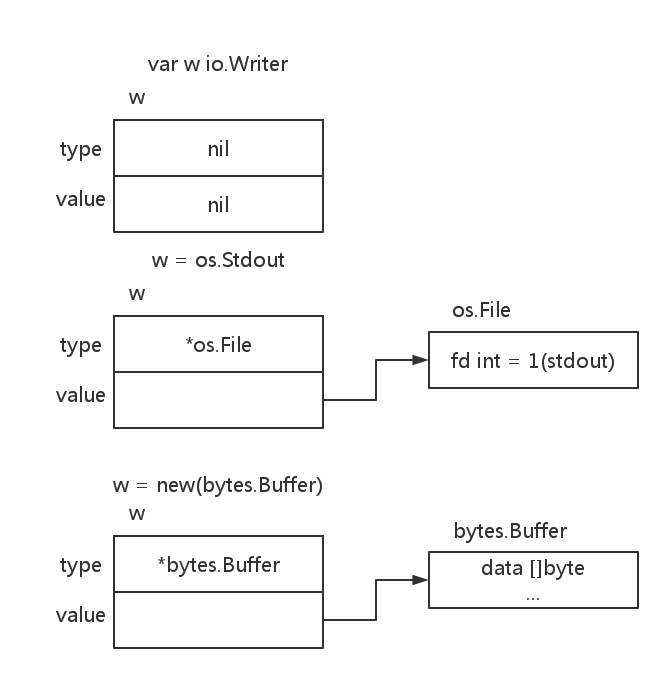
interface类型可以存放任意大的dynamic value,例如
1 | var x interface {} = time.Now() //包含秒,纳秒等信息 |
interface比较
两个interface相等的条件为
- 两个interface都为nil
- dynamic type和dynamic value都相等
如果interface指向了不能比较的类型,而代码中又强行比较的话,会造成panic,如下
1 | var x interface{} = []int{1, 2, 3} |
An interface Containing a Nil Pointer Is Non-Nil
一个nil的interface和一个interface包含一个pointer为nil情况是不同的,如下
1 | const debug = true |
上述程序会panic在out.Write函数,当main调用f时,它会把type信息*byte.Buffer赋值给out的type,nil作为value赋值给out的value,因此,此时out不是nil的interface,于是,out调用write的时候就panic了。
正确的写法是
1 | var buf io.Writer |
接下来三节将会讨论GO标准库的一些interface,包括sorting、web serving和error handling。
Sorting with sort.Interface
在GO中,sort.Interface包含以下内容
1 | package sort |
为了使用标准库的排序算法,我们需要定义一个类型,实现interface的三种方法,例如
1 | type StringSlice []string |
由于排序字符串数组很常见,标准库已经集成了,调用sort.Strings(names)即可。
标准库定义了一个Reverse函数,如下
1 | package sort |
这样sort的时候,使用Reverse就能逆序排序了,sort.Sort(sort.Rerverse(sort.Strings(names)))。
The http.Handler Interface
在GO中,通过net/http,可以实现web server,具体地我们看其是怎么工作的。
1 | package http |
ListenAndServe函数的第一个参数是string,一般接受localhost:8000之类的参数,第二个参数则是一个Handler interface,需要实现ServeHTTP method。
一个简单的使用例子
1 | func main() { |
这个例子对网站的所有路径的访问都会输出相同的东西,如果我们需要通过/price获取价格信息,/list获取列表信息,可以通过以下方法实现
1 | func (db database) ServeHTTP(w http.ResponseWriter, req *http.Request) { |
如果需要处理的访问路径越来越多,switch语句的case也会越来越多,为了方便,net/http提供了ServeMux,可以把一组http.Handler聚合到单个http.Handler中,如下
1 | func main() { |
因为db.list不满足http.Handler interface,因此使用了http.HandlerFunc,如下
1 | type HandlerFunc func(w ResponseWriter, r *Request) |
可以看出,对于函数类型,也可以有method。由于上述功能经常使用到,标准库提供更简单的写法
1 | mux.HandleFunc("/list", db.list) |
The error Interface
error interface的定义如下
1 | type error interface { |
error可以通过errors.New创建,其实现方法如下
1 | package errors |
还可以使用更简便的方法,例如
1 | package fmt |
Type Assertions
Type Assertions一般是x.(T),其中x是interface类型,T是类型,称为asserted类型。Type Assertion检查interface的dynamic type是否和类型T匹配。
- 如果asserted类型是具体的类型,并且dynamic type与之匹配了,那么x.(T)的返回值是x的dynamic value,否则,程序panic。
1 | var w io.Writer |
- 如果asserted类型本身是interface,那么检查dynamic type是否满足T,如果检查通过,dynamic type和dynamic value保持不变,但是interface类型变为T。这种type assertion的意义是可以改变interface的method组合。
1 | var w io.Writer |
type assertion到更少的method组合通常是不必要的,因为可以直接用赋值运算就好,如下
1 | w = rw |
- 如果type assertion带了两个返回值,那么失败的时候不会panic。
1 | var w io.Writer = os.Stdout |
Discriminating Errors with Type Assertions
系统中,I/O可能因为很多原因而失败,但是有三种必须要特殊的处理:file already exist,file not found和permession denied。
系统中提供了三个函数来判断三种错误,如下
1 | package os |
标准库采用如下方法实现
1 | package os |
Querying Behaviors with Interface Type Assertions
在使用net/http包时,会使用到类似下面的函数
1 | func writeHeader(w io.Writer, contentType string) error { |
因为需要把string类型转成[]byte,会分配临时的内存,造成内存使用量过大。对于有些io.Writer,实际上它们是支持WriteString方法的,因此,WriteHeader可以优化成如下
1 | func writeString(w io.Writer, s string)(n int, err error) { |
Type Switches
Interface一般以两种不同的方式在使用。第一种是强调method,例如io.Reader等;第二种是强调type。
考虑下面的代码
1 | import "database/sql" |
为了实现讲不同的类型转换成问号中具体的值,我们可以用以下方法
1 | func sqlQuote(x interface{}) string { |
上面采用的方法是type assertion,需要使用大量的if-else语句,不是太方便。
GO中还支持type switch的方法,支持switch语句,比较方便
1 | func sqlQuote(x interface{}) string { |
PS:
本博客更新会在第一时间推送到微信公众号,欢迎大家关注。
